甚麼是 robots.txt?
今天要帶大家來揭曉SEO公司不會告訴您的 robots.txt 全指南!什麼是 robots.txt 呢?給予 Google 爬蟲一個明確的指示,告訴他該抓取網站哪部分內容的其中一種方法,我們稱之為 robots.txt。
有三種方法可以達成此目的,而同一個頁面只能使用其中一種方式:
- 設定檔名為 ” robots.txt “
- 使用機器人元標記( Robots meta tag )
- 用於 X-Robots 的 HTTP 標頭
當爬蟲訪問您的網站時,他將執行以下動作:
- 檢查名為“ robots.txt ”的檔案,以確定它是否應該訪問您頁面的其餘部分。
- 按照“ robots.txt ”檔中的說明,爬蟲將繼續爬行或停止。
- 是否有索引頁面並追蹤其連結是通過檢查機器人元標記或 x-robots 標頭
“ robots.txt ” 檔中的指令僅提供應如何爬蟲的想法,而機器人元標記中的指令則是給出了更明確的指示。因此,在大多數情況下,不應使用“ robots.txt ”檔來禁止抓取或索引,而是使用“ noindex ”或” follow ”的機器人元標籤。
robots.txt
如同上文所述,網站主目錄中的 robots.txt 檔,是給予爬蟲一個如何瀏覽您網站的指示,而這個指示可以通過控制面板或 FTP 獲得。此外,值得注意的是檔案名稱,應為小寫的「 robots.txt」而不是 Robots.txt 或 ROBOTS.TXT。
然而,使用 robots.txt 檔能夠讓爬蟲忽略特定資料夾和檔案,卻不會阻止搜尋引擎索引和顯示內容的呈現。因此,並不需要擔心加了 robots.txt 檔會發生內容變異的問題。
三個您必須使用 robots.txt 的理由
Robots.txt 文件檔適用於阻止對網站的整個部分(例如某個類別)的訪問。

遠離私人資料夾:
將機器人排除在您的私人資料夾之外,使它們更難找到和索引。由於並非所有爬蟲都會被 robots.txt 檔阻止,因此您更應該使用另一種方法(例如密碼安全性)來防止網站使用者訪問您不希望輕鬆搜索的資訊。
保持資源的可控性(爬蟲預算):
每次機器人訪問您的網站時都會消耗抓取資金,因此限制其訪問許可權非常重要。對於具有數百個頁面的網站(例如電子商務平臺),爬網預算可能會因為爬網程式嘗試載入網站上的每個細節,而導致快速的消耗。
因此,若使用 robots.txt,您將可以限制特定的訪問細節,從而將資源轉移到更重要的頁面上。
提供網站地圖的 URL:
輕鬆獲取網站 URL 的並抓取您的網站。
robots.txt 檔的拒絕指示
利用 robots.txt 檔有很多種方式可以向爬蟲傳遞指令,然而,並非所有的爬蟲都會聽從您的指示,因此要特別注意的是,您不應該過度依賴使用 robots.txt 檔。
以下為 Gremlin Works 為您整理出的 robots.txt 指示簡介:
禁止網路爬蟲使用您的資料
- 瀏覽器/版本: *
- 拒絕:/
防止爬蟲探索某個特定項目
- 使用者代理: *
- 拒絕: /子資料夾/
阻止使用 PDF 檔
- 瀏覽器/版本: *
- 不允許:/directory/some-pdf.pdf
阻止存取某個特定網頁
- 使用者代理: *
- 沒有拒絕訪問/無用的檔.html
阻止看到某個影像
- 使用者代理:Googlebot-Image
- 警告:/images/dogs.jpg 被阻止
防止照片被抓取
使用者代理:Googlebot-Image
- 拒絕:/
- 請注意,如果某個網站與 robots.txt 檔中存在內部連接,Google 仍會抓取該網站。
處理斜線結尾的網址
- 使用者代理: *
- 不允許:/目錄
此指令不會向搜尋引擎打開以下內容:
- /目錄
- /目錄/
- /目錄名稱-1
- /目錄名稱.html
- /目錄名稱.php
- /目錄名稱.pdf
萬用字元
如果使用星號 * 作為萬用字元,它將與您設置的任何條件匹配。用於識別整個爬蟲(廣告機器人除外)或 URL 的一部分(如“ http://www.example.com/ ”)。
防止網站上的任何.html檔被搜尋引擎爬蟲索引
使用者代理: *
忽略所有.html 檔
除了 AdsBot 抓取工具之外,使用星號進行匹配時,需要擁有明確的命名。像是:
僅限制對 Googlebot 的訪問的:
資訊檢索系統使用者代理:Googlebot
拒絕:/
阻止 Googlebot 和 Adsbot 訪問
- 使用者代理:Googlebot
- 使用者代理:AdsBot-Google
- 拒絕:/
停止 AdsBot 之外的所有爬蟲
使用者代理: *
拒絕:/
Google,Bing,Yahoo和Ask等搜尋引擎都支援萬用字元。
所有網路爬蟲都可以存取您的內容
使用者代理: *
禁止:
如果您想阻止某個爬蟲存取您的網站
推薦人: Bingbot
拒絕:/
阻止一個抓取工具存取您的網站,同時讓其他抓取工具通過
不必要的機器人是使用者代理
拒絕:/
使用者代理: *
允許:/
robots.txt 檔的允許指令
在極少數情況下,robots.txt 檔可能會包含著允許指令。允許指令通常是讓爬蟲知道,可以開始對之前所拒絕的部分進行索引。簡單來說,正是利用允許指令將先前的拒絕指令覆蓋過去。
使用者代理: *
請允許:/media/條款和條件.pdf
拒絕: /媒體/
透過 Allow 和 Disallow 指令,您可以為搜尋引擎提供對其他受限目錄的訪問許可權,以便對該目錄中的單個當案或一組頁面進行爬取。
在上述情況下,索引服務被限制進入整個資料夾,但位於介質/條款和條件.pdf中的條款和文檔除外。
允許一個抓取工具(例如Googlebot-news)訪問該網站,同時阻止所有其他抓取工具。
使用者代理:Googlebot-news
允許:/
使用者代理: *
拒絕:/
您可以使用它(順序與前面的示例不同,順序很重要!)
防止您的頁面出現在搜尋結果中,同時仍授權 Mediapartners-Google 分析它們的許可權。
使用者代理: *
拒絕:/
使用者代理:MediaPartners-Google
允許:/
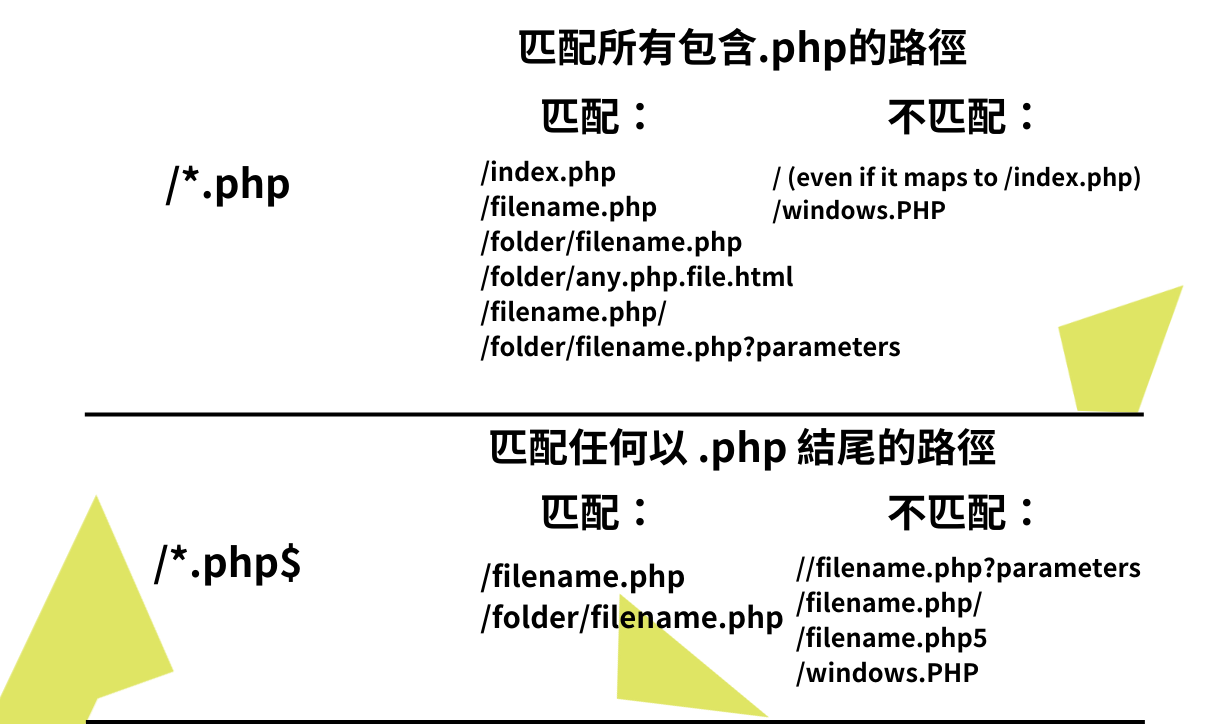
如果要指示 URL 位於其末尾,可以使用美元符號 ($)
使用者代理: *
無法訪問: /*.php$
在上述情況下,並非所有 .php 終止的 URL 都可以被搜尋引擎訪問。
Googlebot 無法索引 GIF 檔
使用者代理:“Googlebot”是
警告: /*.gif$/
Googlebot 無法抓取 XLS 檔
使用者代理:“Googlebot
拒絕: /*.xls$
參數化網址,例如 https://example.com/page.php?lang=en 由於 URL 不以 .php 結尾,因此使用 lang=en 是可以被接受且認可的。



注意事項
- 字元表示註釋,而該註釋可能位於一行的開頭,也有可能緊跟在同一行的指令之後。
- 符號後面的任何內容都將被忽略。
防止訪問敏感數據
為了防止機器人訪問敏感數據,拒絕它們訪問 /wp-admin/ 資料夾,例如:
使用者代理: *
拒絕: /wp-admin/
阻止參數網址
您可以透過執行以下操作防止在參數中使用萬用字元,例如:
停止: /*?
但這並不是最明智的做法,使用此方式,除了阻止爬網程式訪問網站之外,有可能會阻止您不打算禁止的頁面,像是部落客的文章等等。
robots.txt 優先使用原則
在將 robots.txt 規則與 URL 匹配時,爬網程式將會優先採納路徑長度為考量,並使用更加具體的規範。如果有衝突產生時,Google 會選擇更寬鬆的規則。


指明網站地圖的詳細資訊
為了改進 Google 對您網站的索引編制,在 robots.txt 檔中放進網站地圖網址是一個必要的工作。您可以透過以下方式來指引搜尋引擎爬蟲:
使用者代理: *
拒絕: /wp-admin/
在此處,您將可以獲取 Example.com 的網站地圖:https://www.example.com/sitemap 索引.xml,如有必要也可以指定多個網站地圖。
使用者代理: *
禁止:
您可以在 https://www.example.com/people.xml 存取網站地圖。
對於網站地圖,請使用整個網址,而不僅僅是 /sitemap.xml。
指示爬蟲時間延遲
如果抓取工具導致您的網站崩潰或過載,您可以要求他們透過編輯 robots.txt 檔來放慢瀏覽網站的速度。
在 robots.txt 檔中查看它的實際效果,該檔僅將爬網延遲應用於 Bingbot:
使用者代理: *
限制:不允許 /搜索
不得使用 /compare/ URI。
使用者代理:必應機器人
不允許存取: /搜尋/
不允許使用此 URL 方案:/compare/
抓取速度延遲十秒。
網站地圖: https://www.example.com/sitemap.xml
不要花時間在建立 Google 抓取延遲,因為 Google 的爬蟲 Googlebot 並不支援。請改用搜索主控台。如果您擔心一次向伺服器發送過多查詢,可以使用非官方的爬網延遲指令,將抓取延遲放在 robots.txt 檔中充其量僅僅是一種權宜之計。
Robots.txt 的應用指南
- 根據 Google 的說法,robots.txt 檔將在緩存中保留至少一天。在保存對機器人檔的任何修改之前,請考慮這一點。而爬網程式將會遵循讀取檔時的第一條指令。
- Googlebot 可以忽略您使用 robots.txt 進入不太重要的網頁,從而節省最重要的網頁抓取預算。如果頁面不需要顯示某個資源檔,可以透過使用 robots.txt 檔將該檔列入黑名單來阻止其訪問。
- 不允許所有大寫字母。例如: /file.asp 將阻止對 https://www.example.com/file.asp 的訪問,但不會阻止對 https://www.example.com/FILE.asp 的訪問。
- 以井號 (#) 開頭的備註是標準做法。
- 必須將每條指令寫在新指令上。
- Google 不再支持 robots.txt 中的 NoIndex 指令。
- 每個搜尋引擎只允許定義一組指令。單個搜尋引擎中有多組指令,可能會將其混淆。
- 阻止訪問您在機器人中的材料 .txt 如果已被編入索引,則不會將其從 Google 的索引中刪除。
robots.txt在WordPress
以下 robots.txt 指令應該被允許或阻止 WordPress 安裝。
客戶 IP: *
要啟用,請訪問: /wp-content/uploads/
拒絕: /wp-content/plugins/
拒絕: /wp-admin/
robots.txt 檔可以通過根目錄中的 FTP 或使用 Yoast SEO等外掛程式訪問。
使用機器人元標記
請注意,漫遊器元標記和漫遊器.txt檔有不同的用途。如果要阻止訪問整個目錄,請使用robots.txt,但如果您只想阻止訪問一個頁面,請使用漫遊器元標記。
您可能會看到它的格式:meta name=“robots” content=“noindex, nofollow”>,它們將會放置在頁面的頂部,並會指示爬蟲是否索引和關注其頁面。如果不存在漫遊器元標記,系統將會假設其已被編入索引。即使它不會阻止搜尋引擎訪問該網站,它也可能會阻止他們索引材料。
可選元標記
以下為使用元標記的方式:

- all – 這是預設值,與索引相同。
- noarchive – 不會在搜尋結果中顯示緩存的連結。如果您省略此指令,即使您明確禁止這樣做,Google 仍可能會創建該網頁的緩存版本。
- follow – 如果頁面未編入索引,仍應追蹤其所有連結,並向前傳輸連結值。
- nofollow – 不要關注頁面上的任何連結或傳遞任何鏈接權益。
- noimageindex — 不要為頁面上的任何圖像進行索引的編制。
- nosnippet – 不在此頁面的搜尋結果中顯示文字片段或視頻預覽。如果這樣做可以改善用戶體驗,則可以顯示靜態圖片縮圖。
- none – 與同時使用 noindex 和 nofollow 相同。
- 當設置為將來的日期時,此頁面將被標記為“不可用”並從搜尋引擎索引中刪除。
- Noindex 網頁仍然可以嵌入到其他網站中,使用 indexifembedded 標記向 Google 表明即使原始網頁包含 noindex 標記,也應將內容編入索引。
- 代碼段中的最大字元數、圖像預覽的大小和視頻預覽的長度都可以分別使用 max-snippet、max-image-preview 和 max-video-preview 選項進行修改。
短語“nofollow”用於表示不會有連結,以下為 noindex,nofollow 標籤的示例:
<元名稱=“機器人”內容=“noindex, nofollow”>
使用此元機器人標籤,您可以防止搜尋引擎爬蟲索引您的頁面並點擊其任何連結。然而,如果該頁面之前已被編入索引,則搜尋引擎應從搜尋結果中刪除該頁面,且對搜尋引擎索引網頁並沒有影響。
Shopify 的機器人元標記
在 theme.liquid 佈局文件的頭頂部中,您可以為某些頁面添加 noindex 標籤,如下所示:
代碼顯示:“% 如果句中包含’頁面名稱’%”
使用漫遊器元標記可防止您的網站被搜尋引擎編入索引。
X-機器人 HTTP 標頭標籤
為了使用 x-robots 標籤,您需要一個能夠訪問您網站的標題,像是:.php、.htaccess 或伺服器配置檔。如果您無權訪問元機器人標籤,則可以使用元漫遊器標籤為網路爬蟲提供替代說明。
x-robots 應包含在頁面的 HTTP 標頭中。但您不需要在同一頁面上同時使用元機器人和 x-robots-tag ,對於無法使用 x-robots 標記的文件和網站(例如 PDF、電影等),可以使用 x-robots 標題代替漫遊器元標記。它也可以用來對頁面的某些區域進行 noindex,指定全域爬網指令。
為了在網站的 HTTP 回應標頭中包含 X-Robots 標籤,您可以編輯 .htaccess 文件,使用 HTTPd.conf 檔或 NGINX。而對於 X-Robots,您可以使用與之前給出的元標記示例中相同的參數。
延伸閱讀:HTTP HTTPS比較
Apache
想要將 x-robots 擴展到其他檔案格式,可以透過將代碼加入網站中的 root.htaccess 檔或 Apache 的 HTTPd.conf 檔,確保整個網站中,所有 .PDF 檔都帶有 noindex。
使用 X-Robots 阻止訪問特定文件
在 Apache 中,您還可以使用此方法限制對某些文件的訪問:
- # .htaccess 文件必須與匹配檔位於同一資料夾中:(PDF 檔名為“獨角獸.pdf”)
- 將 X-Robots-Tag 在標題中設定為 “noindex, nofollow” 。
X-Robots 被用於阻止抓取整個目錄
使用 X-Robots 無法一次保護整個資料夾。創建一個新的 .htaccess 檔並將其放在要保護的資料夾中。該子目錄中的任何後續頁面或檔也將使用 HTTP 標頭。
假如您希望阻止搜尋引擎索引 WordPress 安裝的/wp-admin/目錄。啟動新的 .htaccess 檔並新增以下規則:將 X-Robots-Tag 在標題中設定為 “noindex, nofollow” 。
您可以使用 FTP 用戶端將此檔案傳輸到 /wp-admin/ 目錄。為了防止搜尋引擎索引和關注位於 /wp-admin/ 目錄中的任何內容,我們在 noindex, nofollow 指令中包含 X-Robots HTTP 標頭標籤。
爬蟲被X-Robots 擊退,但只有某些爬行器。
NGINX
將 X 射線機器人擴展到其他檔案格式
例如,這一行可以添加到 NGINX 上的.conf 檔中,以在整個網站的所有.PDF 檔的 HTTP 回應中附加noindex,nofollowX-Robots-Tag。
找到。*.pdf美元…
包含一次(“添加標題”,“X-Robots-Tag”,“noindex,nofollow”);}
此外,如果您想確保將所有檔.doc和.pdf檔從索引、存檔和片段中排除,這就是您在 NGINX 中放入的內容:
哪裡*。。(doc|pdf)$ 其中
X-Robots-Tag=“noindex, nofollow, nosnippet”;添加標題}
如果您將 NGINX 用於網站的 Web 伺服器,則還可以將其應用於.conf 檔中網站上的所有照片。
*.(png|jpe?g|gif)$ *.位置
X-Robots-Tag=“noindex”;添加標題
使用 X-Robots 阻止訪問特定文件
此外,NGINX的.conf文件允許選擇性檔阻止:
獨角獸.pdf位置 = /機密
包含一次(“添加標題”,“X-Robots-Tag”,“noindex,nofollow”);}
若要阻止訪問某個檔,請使用以下語法:
檔案名稱 = 位置
包含一次(“添加標題”,“X-Robots-Tag”,“noindex,nofollow”);}
。.PHP
要在 PHP 中添加 X-Robots 標籤,請執行以下操作:
這一切都始於標題:標題(’X-Robots-Tag: noindex,nofollow’);
另一種選擇是這個
<? index,archive’); in a PHP header;? >
除非將它們放在檔的最開頭,在任何其他指令之前,否則它們將無法正常運行。
檢查X-Robots的HTTP標頭
在 Google Search Console 中,找到相關代碼,然後點擊網址檢查,然後點擊測試實際網址和查看已抓取的網頁,HTTP 回應詳細信息顯示在「更多資訊」部分中。
限制內容索引:您需要了解的內容
如果您不希望為任何內容編製索引,可以執行以下操作之一:
需要包含NOINDEX 指令和如果您想在網上找到,您必須讓搜尋引擎索引您的材料。為了使 NOINDEX 元標記防止材料被編入索引,搜尋引擎必須能夠抓取它。
與SEO公司一起迎來網站流量高點
看完文章仍對robotstxt的操作感到陌生與困難嗎?別擔心!專業的SEO公司可以幫助您解決操作robotstxt時遇到的難題!SEO公司會協助您控制搜索引擎爬蟲的行為,使重要頁面被索引,不希望公開的內容則得到保護。想增加網頁曝光的您還在等什麼呢?快聯絡Gremlin Works吧!
